AI SEO Experiments
How ChatGPT Researches Your Brand: 182 Queries, Two Modes, and the 93.4% Citation Gap

I just found something wild about how AI searches for your brand.
We all assume tools like ChatGPT just "know" things from their training data. But when you ask about current products or specific recommendations, they go out and browse the web.
So I ran an experiment. I set up a trap - a server-side logging system - to catch EXACTLY what ChatGPT looks for when you ask it about software.
The data was NOT what I expected.
When I compared generic questions ("What's the best CRM?") vs. brand-specific questions ("Is Salesforce good?"), the AI's behavior completely changed.
Generic prompts triggered 64% MORE internal searches than brand-specific ones.
Here's why that matters - and how you can use it to hack your AEO (AI Engine Optimization) strategy.
🧪 THE EXPERIMENT
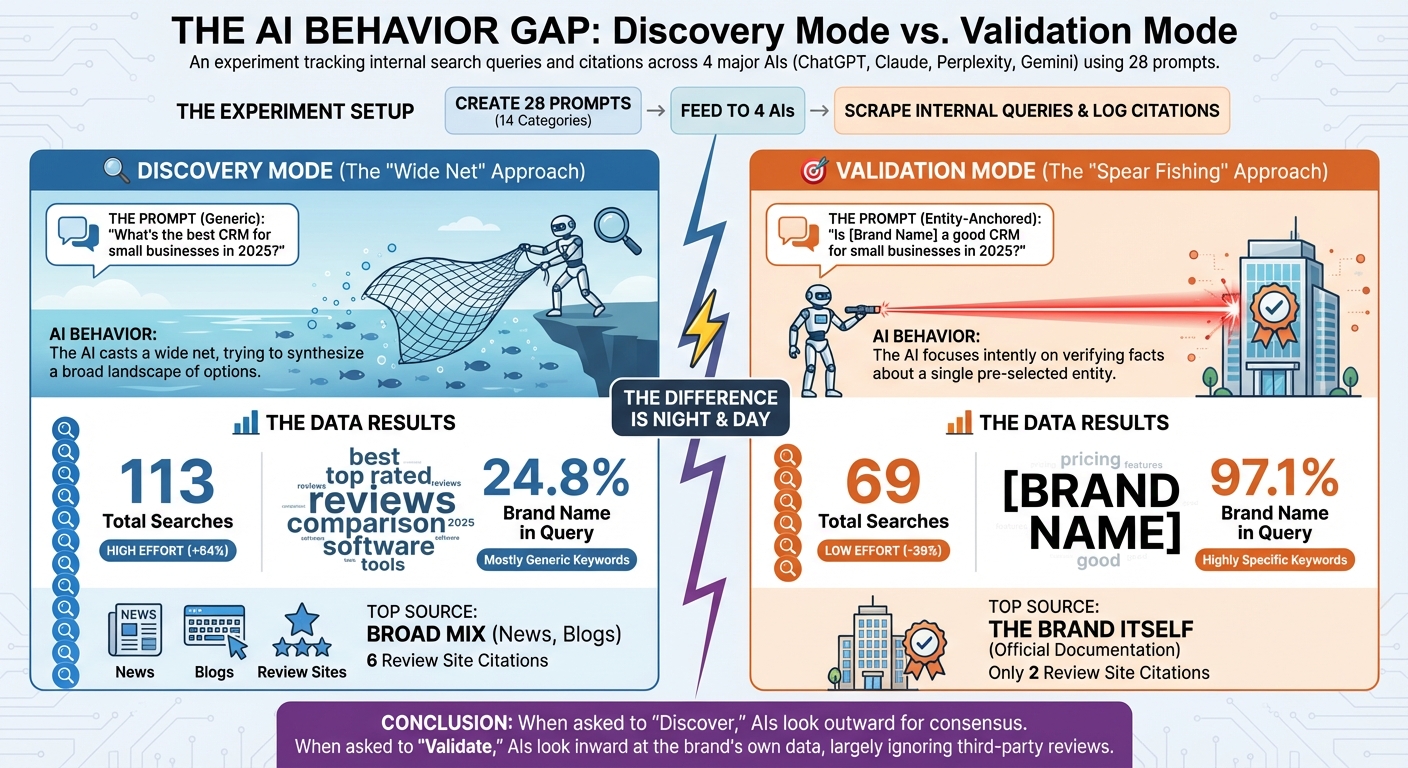
I wanted to see the difference between "Discovery Mode" and "Validation Mode."
So I created 28 prompts across 14 categories (CRM, Project Management, Email Marketing, etc.) and split them into pairs:
1. Generic Prompts:
"What's the best CRM for small businesses in 2025?"
2. Entity-Anchored Prompts:
"Is [Brand Name] a good CRM for small businesses in 2025?"
I fed these into ChatGPT, Claude, Perplexity, and Gemini, and then I scraped the internal search queries (what the AI actually typed into Bing or Google) and logged the citation URLs (what it sent back to the user).
Here is exactly what I found.
📊 THE RESULTS
The difference in behavior was night and day.
| Metric | Generic Prompts ("Best X") | Entity Prompts ("Is Brand Y Good?") |
|---|---|---|
| Total Search Queries | 113 searches | 69 searches |
| Search Volume | High (+64%) | Low (-39%) |
| Brand Name in Query | 24.8% | 97.1% |
| Review Site Citations | 6 citations | 2 citations |
| Top Source | Broad mix (News, Blogs) | The Brand Itself |
🧠 THE INSIGHTS
1. Discovery vs. Validation Mode
Here's the thing...
When you ask a generic question, the AI goes into Discovery Mode. It casts a wide net, searching for "best [category] 2025," "top rated [category]," and "reviews." It's looking for consensus.
But when you ask an entity-specific question, it switches to Validation Mode. It stops looking around and goes straight to the source—your website.
The Insight: Use generic content to get found. Use entity content to close the deal.
2. Reviews Are for Reading, Not Citing
The data showed something interesting about review sites like G2 and Capterra.
The AI searched for them constantly ("salesforce reviews g2", "hubspot pros cons capterra"). It clearly READS them to understand sentiment.
But it almost NEVER cited them.
For generic prompts, review sites were only cited 6 times. For entity prompts? Only 2 times.
Instead, after reading the reviews, the AI went to the brand's own pricing or features page and cited that as the source.
The Bottom Line: You need good reviews to influence the answer, but you need a great website to get the citation.
3. Your Competitors Are Stealing Your "Entity" Traffic
This one hurt to watch.
In the "Other" bucket of citations, I found competitor brands popping up in the answers for specific companies.
Example: When I asked: "Is Klaviyo good for deliverability?" ChatGPT cited: Moosend.com (a direct competitor) 4 times.
Why? Because Moosend wrote a "Moosend vs. Klaviyo" comparison article that answered the specific deliverability question better than Klaviyo's own pages did. The fan-out generation surfaced the comparison page, and Moosend's framing of the comparison won the citation slot.
The mechanic is more general than this one example. ChatGPT runs 2 to 4 sub-queries per complex prompt (the fan-out pattern). Each sub-query becomes a separate retrieval pass with its own candidate pool. If a competitor has written the answer to a sub-query you have not answered, they enter your branded conversation through the back door.
The Insight: If you don't answer specific questions about your own product, your competitors will do it for you. Audit "Brand X vs Brand Y" SERPs for your top competitors and write the comparison from your perspective. If you do not own that conversation, your competitor will.
🔁 THE FAN-OUT MECHANICS BEHIND ENTITY QUERIES
The 64% gap in search volume between generic and entity prompts hides a more useful pattern: ChatGPT runs different kinds of sub-queries depending on intent. From the same 182-query experiment, here is the typical fan-out behavior we observed:
| Prompt type | Typical sub-queries | What ChatGPT is trying to find |
|---|---|---|
| Generic ("best CRM for startups") | "best CRM 2026", "top CRM small business", "CRM software comparison", "[brand] vs [brand] reviews" | Establish the candidate set, find consensus on top picks |
| Entity ("is Salesforce good for startups") | "Salesforce reviews", "Salesforce pricing", "Salesforce features small business", "Salesforce alternatives" | Pull facts from the brand, then check against external opinion |
| Comparison ("Salesforce vs HubSpot") | "Salesforce vs HubSpot", "HubSpot vs Salesforce reviews", "[platform] CRM comparison 2026" | Find a third-party that has compared them head-to-head |
| Validation ("is HubSpot worth it") | "is HubSpot worth it", "HubSpot reviews 2026", "HubSpot pros cons", site-restricted Reddit/forum queries | Heavy on community sentiment; web UI pulls Reddit at 17-46% rates |
This is not a complete taxonomy of fan-out, just the patterns we caught in 182 prompts. The bigger systematic study is at Query Fan-Out Taxonomy. The point: each prompt becomes 2-6 separate retrieval problems, each with its own SERP and its own candidate pool. Optimizing only for the literal user prompt under-serves the actual mechanics.
🤖 PER-PLATFORM: HOW EACH AI RESEARCHES YOUR BRAND DIFFERENTLY
ChatGPT was the focus of the 182-query experiment, but the four major platforms research brands very differently. From our larger 100,411-event corpus (The SEO Floor) plus per-platform crawl analysis:
ChatGPT (Bing-mediated, live fetch). Submits 2-4 sub-queries to Bing per prompt. Fetches pages live via the ChatGPT-User bot. Bing indexing is a prerequisite. Tier 1 (rank 1-3) odds vs Tier 3: 5.16x. Deep-tier UGC share: 16.3%. ChatGPT will pull G2 / Capterra / Reddit during research but tends to cite the brand's own pages or third-party publishers in the answer.
Claude (live fetch, no persistent index). Claude-User checks robots.txt before fetching. Tier 1 odds: 4.94x. Deep-tier UGC share: 0.6% — Claude essentially refuses to cite UGC. For brand research, Claude leans heavily on publisher and editorial sources. If your brand reputation lives on Reddit, Claude will not see it.
Perplexity (proprietary index, freshness-biased). PerplexityBot crawls in the background. Tier 1 odds: 8.61x (steepest rank gradient of the four). Deep-tier UGC share: 24.3% — Perplexity heavily uses Reddit, YouTube, and forums. Strong freshness bias (3.3x fresher than Google for medium-velocity topics).
Google AI Mode (Google Search infrastructure). Inherits Google's authority signals. Tier 1 odds: 7.26x. Deep-tier UGC share: 21.5%. Reddit citations especially prominent for validation queries (71% in our web UI sample for "is X worth it" prompts).
The Bottom Line: A brand strategy that targets only ChatGPT misses the architectural diversity. Building Reddit presence helps Perplexity and Google AI Mode but does nothing for Claude. Investing in editorial-quality publisher coverage helps all four. Investing in your own product documentation helps ChatGPT and Claude more than Perplexity.
📈 THE BIGGER PATTERN: 93.4% OF BRAND CITATIONS DON'T GO TO THE BRAND
The 182-query test surfaces a pattern, but the size of it only becomes obvious when you scale up. Across 2,169 brand-query AI citations we analyzed in a separate study, only 6.6% of citations go to the brand's own pages. The other 93.4% go somewhere else entirely.
| Citation type | Share |
|---|---|
| Third-party publisher (TechRadar, Forbes, Healthline, niche blogs) | ~58% |
| Review sites and aggregators (G2, Capterra, Trustpilot) | ~15% |
| User-generated content (Reddit, YouTube, forums) | ~13% |
| Comparison and listicle pages on competitor or third-party sites | ~7% |
| The brand's own properties | 6.6% |
This is the "earned media bias" Chen et al. (2025) documented in academic research: AI models are trained to prefer sources that look objective and multi-perspective. A brand's own page is inherently single-perspective. An independent comparison or review provides multi-source validation that AI systems treat as higher-quality evidence.
The exception is B2B SaaS, where brand-owned product documentation is so detailed and so unique that no third party can match it. Brand sites hold roughly 48% of citations in B2B SaaS. In every other vertical, third-party dominates.
The practical version: ranking for your own brand name on your own site is not the same as winning AI citations for your brand. The AI will go look at what other sites say about you. If those sites do not exist, are out of date, or get your story wrong, that is what the AI shows users.
🎯 PER-PLATFORM: WHO PREFERS WHOM
The four platforms also weight brand vs third-party differently. Across our larger 100,411-event corpus (The SEO Floor), the share of citations going to user-generated content sources (Reddit, YouTube, forums) for deep-tier citations is:
| Platform | UGC share of deep-tier citations |
|---|---|
| Claude | 0.6% (effectively zero) |
| ChatGPT | 16.3% |
| Google AI Mode | 21.5% |
| Perplexity | 24.3% |
Claude essentially refuses to cite UGC. If your brand reputation lives on Reddit, Claude will not see it. Perplexity, by contrast, leans heavily on UGC for the long tail. The platform mix you target should match where your earned coverage actually exists.
For a brand strategy, this means:
- Claude-heavy audience? Invest in publisher coverage and editorial-quality review sites. Reddit threads will not help.
- Perplexity-heavy audience? Reddit AMAs, YouTube reviews, and forum presence pay off.
- ChatGPT or Google AI Mode-heavy audience? Mix of both, with publisher coverage carrying more weight than UGC.
🛠️ THE PLAYBOOK
So, how do we turn this into traffic? Here is your new AEO checklist.
To Win Generic Queries ("Best [Category] 2025")
These queries are high-volume but competitive. You need to be everywhere.
1️⃣ Year-Stamp Everything: 77% of generic queries included a year. If your content doesn't say "2025," you're invisible. 2️⃣ Get on the Lists: The AI cites "Best X" lists from authoritative domains (TechRadar, Forbes, niche blogs). Get your PR team on this. 3️⃣ Target "Best X for Y": Don't just rank for "Best CRM." Rank for "Best CRM for real estate agents."
To Win Entity Queries ("Is [Your Brand] Good?")
These queries are lower volume but HIGHER intent. You must own these.
1️⃣ Own Your "Vs" Pages: Write the definitive "Us vs. Them" comparison. If you don't, they will. 2️⃣ Create "Feature" Documentation: The AI loves citing specific feature pages (e.g., "Pricing," "API Documentation," "Security"). Make these easy to read. 3️⃣ Don't Ignore Reviews: Even if they aren't cited, they shape the sentiment of the answer. Keep your G2 profile clean.
CHEERS!
The data is clear: AI doesn't just "know" things—it actively researches them.
If users don't know you yet, you're fighting for generic visibility against the entire internet. If they DO know you, you better make sure you control the narrative—or a competitor will be happy to do it for you.
Time to update those year-stamps. 🚀