AI SEO Experiments
Content Shelf-Life and AI Citation: When AI Stops Trusting Your Links

🤔 THE QUESTION
I've been running experiments on how AI search engines actually cite sources - and the data was wild.
Here's the thing: we talk a lot about traditional SEO. Backlinks. Domain authority. Keywords. But what about when an AI assistant decides whether to cite YOUR content vs. someone else's?
I built a custom "Recency Probe" -- a Python engine that runs queries through the Perplexity API and Google's Search API, scrapes the top results, and mathematically calculates when cited sources go stale.
The question: How old can a link be before the AI stops trusting it?
I tested 30 queries across three velocity categories:
- High Velocity: Breaking news, time-sensitive (crypto prices, sports scores)
- Medium Velocity: Reviews, documentation (best laptops 2025, software docs)
- Low Velocity: Evergreen content (history, CSS concepts)
The results completely changed how I think about content freshness. Let me show you what I found.

🧪 THE EXPERIMENT
For the methodology nerds (I respect you), here's exactly what I did:
1️⃣ Query Definition – Tagged 30 queries with velocity categories (High, Medium, Low) to enable stratified analysis.
2️⃣ API Calls – Hit both Perplexity (sonar-pro model) and Google Custom Search API, requesting the top 8 results for each query.
3️⃣ Age Extraction – For each URL returned, I built a date extractor that downloads the page, parses the publication date using htmldate, and calculates: age_days = today - pub_date.
4️⃣ Data Assembly – Merged everything into a CSV with query, category, engine, rank, URL, publication date, and age in days.
5️⃣ Statistical Analysis – Grouped by engine and category to compute mean, median, and 95th-percentile ages for just the top 3 citations.
All automated. All reproducible. No cherry-picking results.
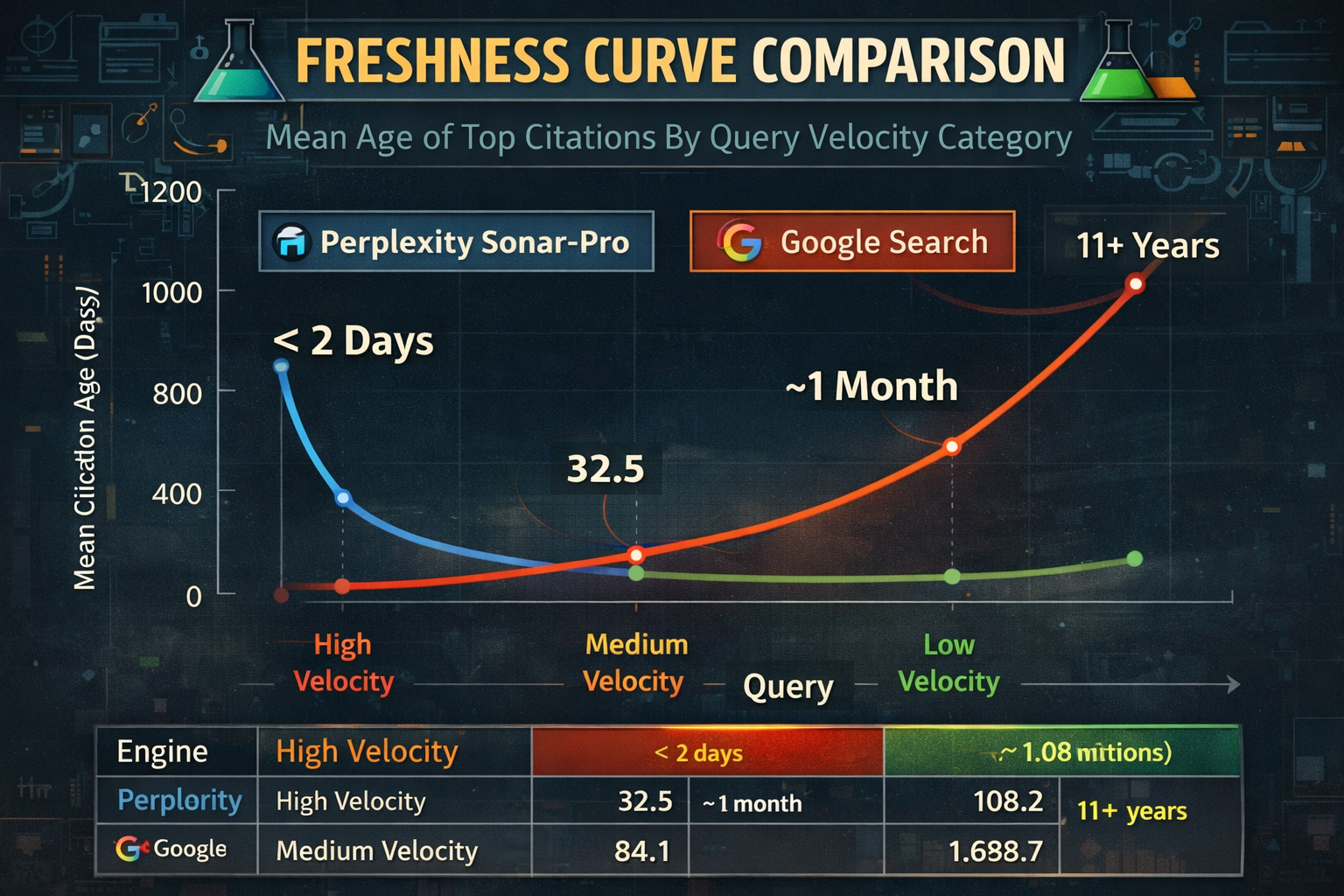
📊 THE RESULTS
Here's where it gets interesting.
| Engine | Category | Mean Age (days) | Median Age (days) | 95th-Percentile Age |
|---|---|---|---|---|
| Perplexity | High Velocity | 1.8 | 0 | 34 |
| High Velocity | 28.6 | 2 | 346 | |
| Perplexity | Medium Velocity | 32.5 | 29 | 214 |
| Medium Velocity | 108.2 | 40 | 193 | |
| Perplexity | Low Velocity | 84.1 | 25 | 1,125 |
| Low Velocity | 1,089.7 | 365 | 4,372 |
Read that last row again.
Google's Low Velocity citations can be over 11 years old and still rank. Perplexity? Under 3 months on average.
The data showed something wild: Perplexity consistently surfaces fresher results across ALL categories. For High Velocity queries, their average citation age is under 2 days. Google's averaging nearly a month.
Real-World Examples from the Data
Let me give you some concrete examples from my dataset.
For the query "bitcoin price support levels today", Perplexity cited three URLs all dated December 21, 2025 - making them 0 days old at collection time. Google's top result? From November 19, 2025 - 32 days stale.
Here's one that really surprised me: For "who signed the Magna Carta", Perplexity returned a citation from December 10, 2025 (11 days old). Google's top result? From January 1, 2014 - over 4,372 days old.
That's the range we're talking about. Days vs. decades.
Even more interesting: for "python list comprehension syntax", Google's #5 result was actually from the same day as collection (docs.python.org updates its dates automatically). But the pattern held - Google's Low Velocity results were overwhelmingly older.
🧠 THE 3 BIG INSIGHTS
Let me break down what this actually means for your content strategy. (For a full framework, see our guide on content strategy for AI search.)
1. High Velocity: The "Container vs. Content" Split
For a query like "inflation rate today," I found something fascinating.
Google's #1 result was a BLS.gov page from 2023 - over 1,000 days old. But Perplexity's #1 result? A PDF released that same week.
The Insight: Google ranks the Container (the trusted, permanent URL). Perplexity ranks the Content (the specific, new file).
Same query. Completely different philosophies.
Google is betting that the old BLS.gov URL will update itself with fresh data. Perplexity is going directly to where the new information actually lives.
2. Medium Velocity: The "Lazy Gap"
For queries like "best gaming laptop 2025," the gap is even more stark.
Google's top results average 193 days old. That's over 6 months.
Perplexity? Finding content from the last 30 days.
The Insight: Google is "lazy" with reviews - it lets old authority sites sit at #1 because they've accumulated backlinks and trust signals. Perplexity is ruthless: if you aren't brand new, you aren't there.
This creates a strategic window I'm calling the Lazy Gap. Google is vulnerable to anyone who publishes fresh, well-optimized content in these niches.
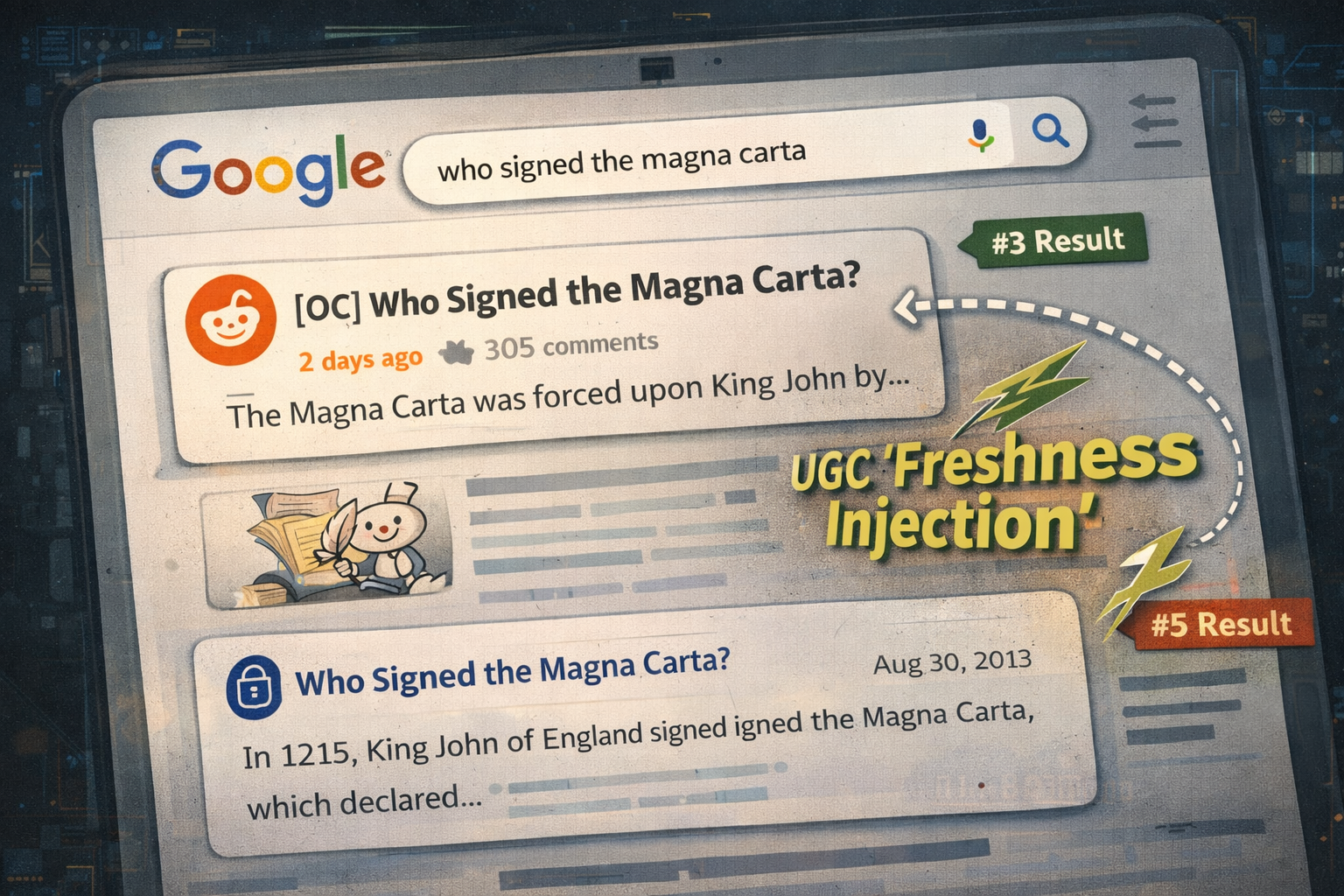
3. Low Velocity: Google is Faking Freshness
Here's what drives me crazy about Google's approach to evergreen content.
For a history query like "who signed the Magna Carta," Google inserted a 2-day-old Reddit thread into the top 5 results. Right next to 10-year-old academic articles.
The Insight: Google uses User-Generated Content (Reddit, Quora) to artificially inject "freshness" into boring, stale SERPs.
They're gaming their own system. The actual authoritative sources are ancient, so they sprinkle in fresh UGC to make the page look alive.
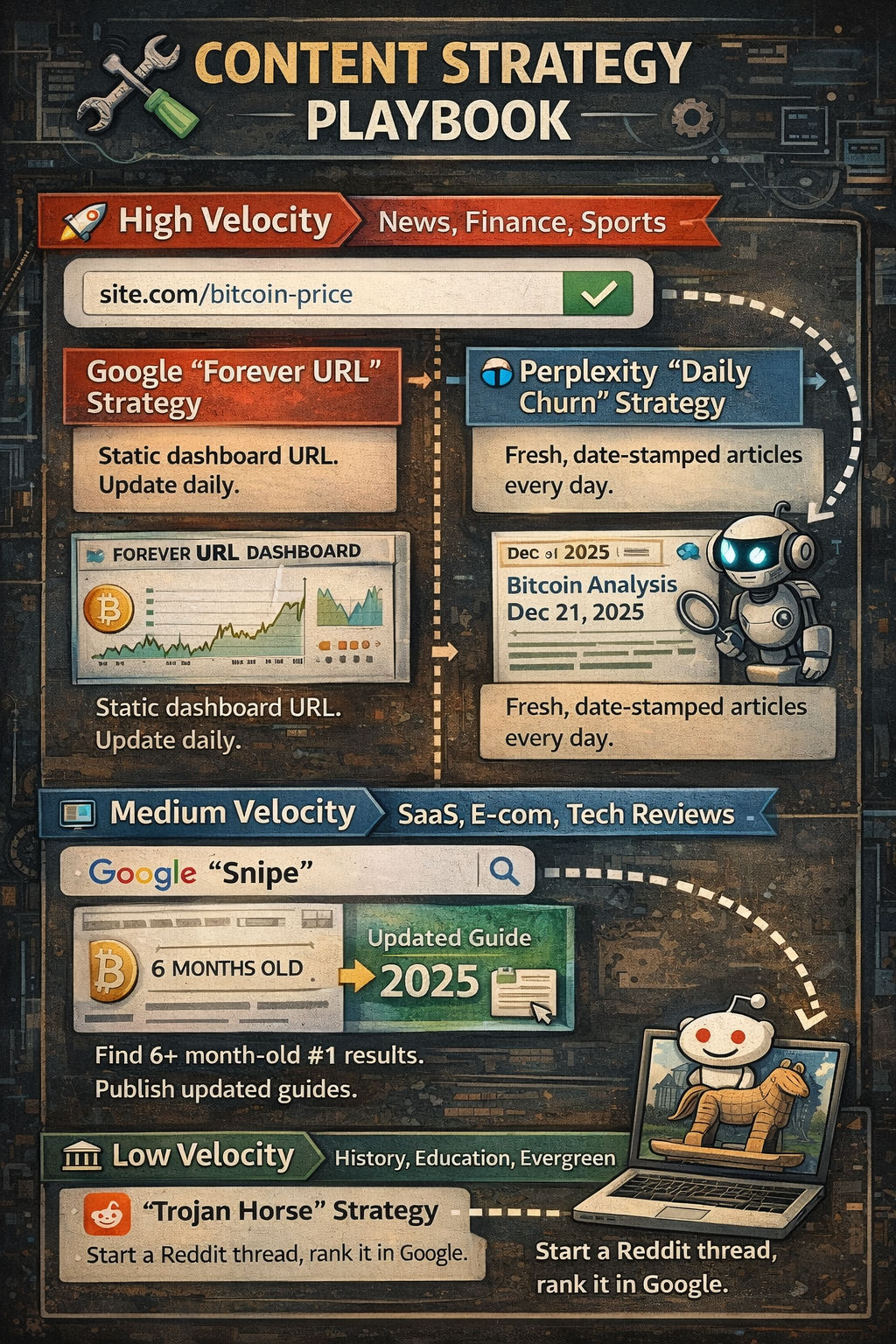
🛠️ THE PLAYBOOK
Here's exactly how to adjust your strategy based on how fast your industry moves.
🚀 High Velocity (News, Finance, Sports)
For Google: The "Forever URL" Strategy
Don't publish a new URL every day. Build ONE static dashboard URL (.../bitcoin-price) and update the data inside it daily.
Google wants the old link with new text. Give it to them.
For Perplexity: The "Daily Churn" Strategy
Publish specific, date-stamped analysis pieces ("Bitcoin Analysis Dec 21"). Perplexity hunts for these fresh URLs.
Different engines, different tactics.
💻 Medium Velocity (SaaS, E-com, Tech Reviews)
The Google "Snipe"
Look for keywords where the top result is >6 months old. Publish a guide updated for 2025.
Google's Lazy Gap means you can steal the snippet simply by being the only fresh option. I'm serious - the data supports this.
The Perplexity "6-Month Rule"
If your documentation or product pages haven't been updated in 180 days, Perplexity thinks they're expired.
Refresh your dateModified schema quarterly to stay visible. It's that simple.
🏛️ Low Velocity (History, Education, Evergreen)
The "Trojan Horse" Strategy
Since Google is forcing Reddit into these SERPs to look fresh, don't just write a blog post.
Start a Reddit thread about your topic.
Why? It's faster to rank a 2-day-old Reddit thread on Page 1 than it is to rank a new blog post on a stale domain.
Use the system they built.
💡 PRO TIP: Publication Date Metadata
Here's something the data revealed that most people miss.
Perplexity returned a valid publication age for >90% of top-3 URLs.
Google failed to provide a date for a non-trivial subset (recorded as None in my data).
What this means: If your content doesn't have explicit, parseable publication date metadata, you're invisible to AI engines that prioritize freshness.
Add proper datePublished and dateModified schema markup. Now. Our AI citation optimization guide covers the full list of metadata signals that influence whether AI engines trust and cite your content.
🌐 EXTENDING THE EXPERIMENT TO ALL FOUR PLATFORMS
The original 30-query test ran against Perplexity and Google only. Since then, we have expanded the corpus to all four major AI platforms across 2,000 queries (The SEO Floor). Here is the freshness picture across the broader sample.
The headline freshness ranking holds, but the story is more nuanced than "Perplexity fresh, everything else stale":
| Platform | Architecture | Effective freshness behavior |
|---|---|---|
| Perplexity | Pre-built index, aggressive recrawl | Most freshness-biased. Median citation age much lower than Google. |
| ChatGPT | Bing index + on-demand fetch | Stale as Bing's index. ChatGPT-User can fetch fresh content but only if Bing knows the URL exists first. |
| Claude | Live fetch with publisher bias | Fresh if the publisher rebuilds frequently; stale if not. Claude's preferred sources tend to be establishment publishers (NYT, Reuters, Bloomberg) who update on news cycles, so freshness varies with the publisher rather than the page. |
| Google AI Mode | Google index | Inherits Google's freshness behavior. Established authority pages persist longer than on Perplexity. |
The implication: optimizing for "freshness" is platform-specific. The Perplexity playbook (publish-and-refresh on a 60-90 day cycle) does not transfer cleanly to ChatGPT, where Bing index inclusion matters more than publish date. It does not transfer to Claude either, where the publisher you publish on matters more than how recently you wrote.
⏱️ TIME-TO-CITATION: HOW FAST DOES NEW CONTENT GET PICKED UP?
A separate question from "what's the median citation age" is "how long after publication can my content first appear?" This is the time-to-citation metric, which we tracked on a smaller sample of newly published pages.
Approximate observed lags from publication to first AI citation:
- Perplexity: 1-7 days for a well-discovered URL (sitemap submitted, robots.txt allowing PerplexityBot)
- ChatGPT (via Bing): 7-30 days, gated by Bing's index update cycle. Bing Webmaster Tools URL submission shortens this.
- Claude: 14-60+ days. Claude often does not fetch newly-published content if its training-data version of "the answer" is judged sufficient. New content gets pulled in primarily when the existing answer is clearly outdated by user signal.
- Google AI Mode: depends on standard Google indexation cycle for the page (typically 1-7 days for established sites, longer for newer domains)
If you publish today and want the fastest AI exposure, prioritize Perplexity discovery (sitemap, freshness signals) and Bing Webmaster Tools URL submission for the ChatGPT path. Wait the Claude lag out, or accept it.
🔁 WHAT COUNTS AS A "SUBSTANTIVE UPDATE"?
We get asked this often. Changing the displayed dateModified without actually updating content is detectable. AI parsers compare your stated date against the page's content drift, your sitemap lastmod, your Last-Modified HTTP header, and (for some platforms) prior crawl snapshots. If those signals disagree, parsers default to the older signal.
What does count as substantive:
- New data points or statistics that were not in the prior version
- Updated comparison tables with current pricing, features, or rankings
- Revised recommendations with explanation of what changed
- New sections added to address questions or angles missing in the original
- Removed sections for content that is now wrong (and an explanatory note)
What does not count:
- Changing the date in the schema or in the visible "Last updated" banner with no body change
- Cosmetic edits (typos, punctuation)
- Adding a single sentence
- Reordering sections without adding information
A good rule of thumb: if a reader who saw the old version would feel they got real new value from the new one, it counts. If not, it doesn't.
⚠️ THE LIMITATIONS
Look, I'll be honest - - this experiment has boundaries:
- Only sampled top-3 citations (higher ranks may behave differently)
- Date extraction depends on explicit metadata (many pages lack it)
- Single snapshot in January 2026 (seasonal effects possible)
- English-language queries only
But the core patterns are clear enough to act on.
🔮 WHAT'S NEXT
I'm not done with this experiment. Here's what I'm planning:
Longitudinal Monitoring - I want to run this same methodology over several months to see if freshness thresholds change with seasons or news cycles.
Domain-Scale Testing - Do established domains get more freshness leeway than new sites? I suspect yes, but I want data.
Forced Re-Indexing - What happens if I submit a URL directly to Bing Webmaster Tools (Perplexity's source) vs. letting it crawl naturally? How much faster does content get cited?
Multi-Engine Expansion - Claude, ChatGPT search, and other emerging AI search tools likely have their own freshness behaviors. The landscape is only getting more complex.
🧠 THE BOTTOM LINE
The data tells a clear story:
- Perplexity has a freshness bias - citations average days old, not months
- Google has a latency tolerance - especially for evergreen content where citations can be years stale
- The "Lazy Gap" for Medium Velocity queries is your strategic window
- AEO (AI Engine Optimization) tactics must be velocity-specific
Here's your cheat sheet:
| Query Velocity | Google Strategy | Perplexity Strategy |
|---|---|---|
| High | Forever URL + daily updates | Date-stamped fresh content |
| Medium | Target >6mo stale keywords | Quarterly freshness refreshes |
| Low | Leverage Reddit/UGC | Structured metadata focus |
Understanding these dynamics lets you allocate resources efficiently and maximize the likelihood that YOUR content gets selected as a trusted citation by AI assistants.
This is the new game.
CHEERS! 🍻