AI SEO EXPERIMENTS
We Tested Whether Google Knowing Who You Are Helps AI Cite You. It Doesnt.

We checked whether Google formally recognizing your brand as a "known entity" makes AI platforms more likely to cite you. It does not. In fact, the domains Google knows BEST are actually LESS likely to be cited by AI. Here is why.
There is a popular theory in the SEO world that goes like this: if Google recognizes your brand in its Knowledge Graph (the database behind those info boxes you see on the right side of Google search results), then AI platforms will trust you more and cite you more often.
The logic sounds solid. Google's Knowledge Graph is like an encyclopedia of known things: companies, people, places, products. If Google has catalogued your brand as a real, recognized entity, surely that signals trust. And if Google trusts you, maybe ChatGPT and Perplexity do too.
We tested this with data from 5,101 websites. The answer surprised us.
🔍 WHAT IS THE KNOWLEDGE GRAPH? (SIMPLE VERSION)
When you Google "Apple" and see a box on the right side showing Apple's logo, stock price, founders, and headquarters, that information comes from Google's Knowledge Graph. It is Google's database of things it considers "known entities" in the world.
Google's Knowledge Graph contains information about:
- Companies and organizations (Apple, BBC, Amazon)
- People (celebrities, politicians, scientists)
- Places (cities, landmarks, countries)
- Products, movies, books, and more
Each entity gets a score that represents how prominent and well-documented it is. BBC has a score of 8,905. Bitwarden (a password manager) has a score of 10,418. Higher scores mean Google has more information about that entity.
The theory we tested: If Google formally recognizes your website as a known entity, are AI platforms (ChatGPT, Perplexity, Google AI Mode) more likely to cite you?
🧪 WHAT WE DID
We took every website from our 10,293-page study (the same dataset where we tested which page features predict AI citation) and checked each one against Google's Knowledge Graph.
The steps:
Extracted 5,101 unique domains from our dataset (every website that appeared in either Google's top 20 results or any AI platform's citations across 250 questions)
Queried Google's Knowledge Graph API for each domain. For example, for "nerdwallet.com" we searched for "NerdWallet" in the Knowledge Graph.
Recorded 8 measurements for each domain:
- Does Google have an entity for this brand at all? (yes/no)
- What is the entity's prominence score?
- Does the entity name match the domain name?
- How many "types" does Google assign? (Corporation, Website, Software, etc.)
- Does it have a short description?
- Does it have a detailed Wikipedia-style description?
- Is it classified as an Organization?
- Is it classified as a Brand?
Compared these measurements against whether each domain was cited by any AI platform
😮 THE SURPRISE: IT GOES THE WRONG DIRECTION
Here is what we expected to find: domains that Google recognizes as known entities should get cited MORE by AI.
Here is what we actually found:
| Measurement | Domains that AI CITED | Domains that AI DID NOT CITE |
|---|---|---|
| Has a Knowledge Graph entity | 70.3% | 75.8% (higher!) |
| Has a detailed description | 40.6% | 48.3% (higher!) |
| Average Knowledge Graph score | 1,556 | 2,141 (higher!) |
The domains AI did NOT cite scored higher on every Knowledge Graph measurement.
Not-cited domains were more likely to have Knowledge Graph entries. They were more likely to have detailed descriptions. And they had higher prominence scores. Everything went backwards from what we expected.
How well does it predict? (Not well)
We built a computer model using all 8 Knowledge Graph measurements to try to predict which domains get cited. Its accuracy: 57.7%.
To put that in perspective:
| What we used to predict | Accuracy (AUC) |
|---|---|
| Random coin flip | 50.0% |
| Knowledge Graph features | 57.7% |
| Page content features | 67.3% |
| Domain enriched features | 68.7% |
| SERP co-occurrence (topical breadth) | 92.1% |
The Knowledge Graph is barely better than flipping a coin. It is the weakest predictor we have ever tested. Meanwhile, topical breadth (how many different searches your site ranks for) predicts at 92.1%.
🤔 WHY DOES BEING "KNOWN" HURT?
This result seems backwards. Why would Google knowing who you are make you LESS likely to be cited by AI?
The answer is not that Knowledge Graph recognition actually hurts. It is a trick of how our data is set up. Here is the explanation in simple terms:
Think about who is in the "not cited" group. Our not-cited domains are websites that rank in Google's top 20 but that AI did NOT cite. What kind of websites rank well on Google? Big, well-known ones. BBC. Amazon. Wikipedia. Government websites. University pages. These are exactly the domains Google's Knowledge Graph knows best.
Now think about who is in the "cited" group. AI platforms cite a mix of well-known domains AND specialized niche sites. A website like rtings.com (which tests and reviews electronics with detailed data) gets cited consistently by AI, even though it has a lower Knowledge Graph score than BBC. Why? Because it produces exactly the kind of structured, data-rich comparison content AI platforms love (as we found in our page features study).
The pattern: Big, famous domains dominate Google's rankings. They also dominate Google's Knowledge Graph. But AI platforms do not cite every famous domain for every query. They cite the domains with the most useful content for that specific question. So our not-cited group is full of famous-but-not-useful-for-this-query domains, which inflates the Knowledge Graph scores of the not-cited group.
In short: being famous gets you into Google's top 20. Being in Google's top 20 puts you in our not-cited comparison group. So fame appears to predict non-citation, but it is really just predicting "ranks on Google," which is where we drew our comparison sample from.
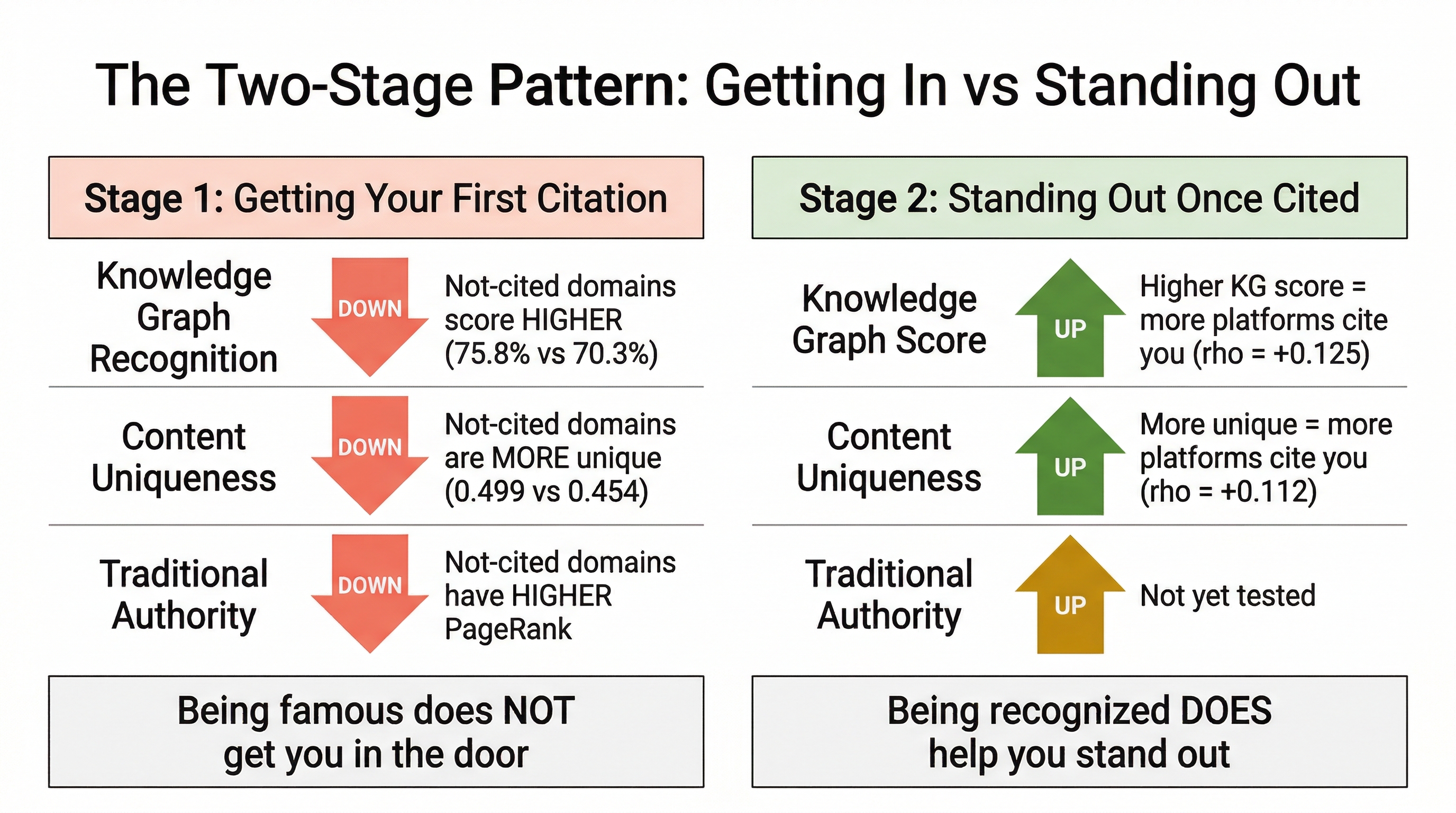
🔄 THE TWO-STAGE PATTERN: GETTING IN VS STANDING OUT
Here is where it gets interesting. We found the same pattern with Knowledge Graph scores that we found with content uniqueness in our earlier study:
Stage 1 (Getting your first citation): Knowledge Graph recognition does NOT help. In fact, not-cited domains score higher.
Stage 2 (Getting cited by MULTIPLE platforms): Among domains that ARE already cited, higher Knowledge Graph scores DO predict being cited by more platforms.
| What we measured | Stage 1: Getting cited at all | Stage 2: Being cited by 3+ platforms |
|---|---|---|
| Knowledge Graph score | Goes the WRONG direction | Goes the RIGHT direction (rho = +0.125) |
| Content uniqueness | Goes the WRONG direction | Goes the RIGHT direction (rho = +0.112) |
| Traditional authority (PageRank) | Goes the WRONG direction | Not tested |
This suggests that getting cited and becoming broadly recognized are two different games:
Getting in the door requires topical coverage and content quality. You need to rank for multiple related searches (topical authority) and have well-structured, data-rich pages. Whether Google formally knows who you are does not matter at this stage.
Standing out once inside is where recognition starts to help. If you are already getting cited, being a well-known entity correlates with getting cited by MORE platforms. But you have to earn the first citation through content quality before recognition kicks in.
✅ WHAT THIS MEANS FOR SITE OWNERS
Do NOT invest effort in "getting into Google's Knowledge Graph" for AI visibility
The data does not support it. Some SEO agencies recommend Knowledge Graph optimization (creating Wikipedia pages, building entity associations, structured data for entity recognition) as a strategy for AI visibility. Our data shows this has no meaningful relationship with whether AI platforms cite you.
The Knowledge Graph is useful for Google's own features (knowledge panels, entity disambiguation, voice search answers). But for AI citation? It is essentially irrelevant.
Instead, focus on what actually works
Based on our full research program (Experiment M), these are the things that predict AI citation:
At the website level (biggest lever):
- Rank in Google's top 20 for 4+ related questions in your topic area. Domains that do this have an 87% AI citation rate. This is topical authority, and it is 10x more predictive than Knowledge Graph recognition.
At the page level:
- Comparison structure ("X vs Y" tables, side-by-side breakdowns)
- The exact words people search for, early in the page
- Deep subheadings (lots of H3 headers)
- Statistics and real data
- Objective tone (not "I think" blog style)
- FAQ sections with FAQ schema markup
- About 2,000 words
For a free check of your pages: AI Visibility Quick Check
The authority metrics that do NOT predict AI citation
We have now tested five types of "authority" metrics against AI citation data. None of them work:
| Authority metric | What we expected | What we found |
|---|---|---|
| Google Knowledge Graph score | Higher = more cited | Wrong direction |
| PageRank | Higher = more cited | Wrong direction |
| Wikipedia inlinks | More = more cited | Wrong direction |
| Domain age | Older = more cited | Wrong direction |
| Backlink count | More = more cited | Wrong direction |
Every traditional authority metric goes the wrong direction. The websites AI platforms trust are not the biggest or oldest or most linked-to. They are the ones that show up across many related searches and produce structured, data-rich content.
❓ FREQUENTLY ASKED QUESTIONS
What is the Google Knowledge Graph?
It is Google's database of known things in the world: companies, people, places, products. When you search for a well-known brand on Google and see an information box on the right side of the page, that data comes from the Knowledge Graph. Google assigns each entity a prominence score based on how well-documented it is.
Should I try to get my brand into the Knowledge Graph?
For AI citation purposes, no. Our data shows Knowledge Graph recognition has almost no predictive power for AI citation (AUC = 0.577, barely above coin-flip level). The Knowledge Graph is useful for Google's own features (knowledge panels, voice search) but not for getting cited by ChatGPT, Perplexity, or Google AI Mode.
Why do all the traditional authority metrics go the wrong direction?
Because our comparison group (not-cited domains) comes from Google's top 20 search results. These are websites Google already considers authoritative enough to rank. They naturally score high on authority metrics. Meanwhile, AI platforms also cite niche, specialized domains that rank lower on traditional authority but produce exactly the content AI needs (comparisons, data, structured information).
If being famous does not help, what DOES help?
Topical breadth (ranking for many related searches) is the strongest predictor at AUC = 0.921. Page-level content features (comparison structure, subheadings, statistics, objective tone) predict at AUC = 0.673. These are behavioral and content signals, not identity signals. AI does not care who you are. It cares what your page contains and how often your domain shows expertise across a topic.
What is the "two-stage pattern" and why does it matter?
We found a consistent pattern across multiple experiments: the things that help you get your FIRST AI citation are different from the things that help you get cited by MULTIPLE platforms. Getting your first citation requires topical coverage and content quality. Getting cited by 3+ platforms is where recognition (Knowledge Graph score, content uniqueness) starts to matter. You have to earn your way in through content before identity signals help you stand out.
🔬 METHODOLOGY NOTES
- 5,101 unique domains queried against Google Knowledge Graph Search API
- 3,671 (72%) returned at least one entity result
- 1,684 (33%) had a name match between entity and domain
- 3,538 domains cited by at least one AI platform; 1,563 not cited
- Balanced Random Forest model: 10 random downsamples, 5-fold CV per run
- All domains from Experiment M dataset (250 queries, 3 AI platforms, Google top-20 SERPs)
- Spearman correlations for continuous features; chi-squared for categorical
- Two-stage analysis: Separate correlation tests for (1) cited vs not-cited and (2) among cited, number of platforms citing
📚 REFERENCES
- Lee, A. (2026c). "I Rank on Page 1: What Gets Me Cited by AI?" Preprint. Paper | Dataset
- Lee, A. (2026a). Query Intent and Google Rank as Joint Predictors of AI Citation: A Multi-Platform Observational Study. Preprint v6. DOI
- Aggarwal, P., Murahari, V., Rajpurohit, T., Kalyan, A., Narasimhan, K., & Deshpande, A. (2024). "GEO: Generative Engine Optimization." KDD 2024. DOI